对着眼前黑色支撑的天空 / 我突然只有沉默了
我驾着最后一班船离开 / 才发现所有的灯塔都消失了
这是如此触目惊心的 / 因为失去了方向我已停止了
就象一个半山腰的攀登者 / 凭着那一点勇气和激情来到这儿
如此上下都不着地地喘息着 / 闭上眼睛疼痛的感觉溶化了
--达达乐队《黄金时代》
好几个地方看到这个 Facebook - Needle in a Haystack: Efficient Storage of Billions of Photos,是 Facebook 的 Jason Sobel 做的一个 PPT,揭示了不少比较有参考价值的信息。【也别错过我过去的这篇Facebook 的PHP性能与扩展性】
图片规模
作为世界上最大的 SNS 站点之一,Facebook 图片有多少? 65 亿张原始图片,每张图片存为 4-5 个不同尺寸,这样总计图片文件有 300 亿左右,总容量 540T,天! 峰值的时候每秒钟请求 47.5 万个图片 (当然多数通过 CDN) ,每周上传 1 亿张图片。
图片存储
前一段时间说 Facebook 服务器超过 10000 台,现在打开不止了吧,Facebook 融到的大把银子都用来买硬件了。图片是存储在 Netapp NAS上的,采用 NFS 方式。
图片写入
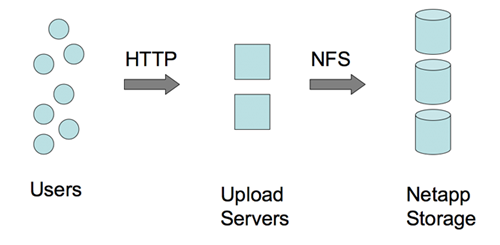
尽管这么大的量,似乎图片写入并不是问题。如上图,是直接通过 NFS 写的。
图片读取
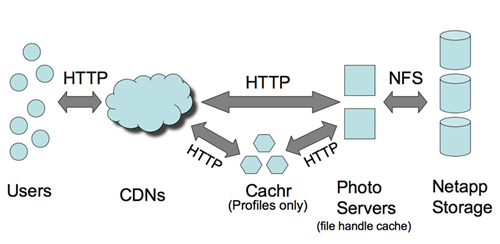
CDN 和 Cachr 承担了大部分访问压力。尽管 Netapp 设备不便宜,但基本上不承担多大的访问压力,否则吃不消。CDN 针对 Profile 图象的命中率有 99.8%,普通图片也有 92% 的命中率。命中丢失的部分采由 Netapp 承担。
图中的 Cachr 这个组件,应该是用来消息通知(基于调整过的 evhttp的嘛),Memcached 作为后端存储。Web 图片服务器是 Lighttpd,用于 FHC (文件处理 Cache),后端也是 Memcached。Facebook 的 Memcached 服务器数量差不多世界上最大了,人家连 MYSQL 服务器还有两千台呢。
Haystacks --大海捞针
这么大的数据量如何进行索引? 如何快速定位文件? 这是通过 Haystacks 来做到的。Haystacks 是用户层抽象机制,简单的说就是把图片元数据的进行有效的存储管理。传统的方式可能是通过 DB 来做,Facebook 是通过文件系统来完成的。通过 GET / POST 进行读/写操作,应该说,这倒也是个比较有趣的思路,如果感兴趣的话,看一下 GET / POST 请求的方法或许能给我们点启发。
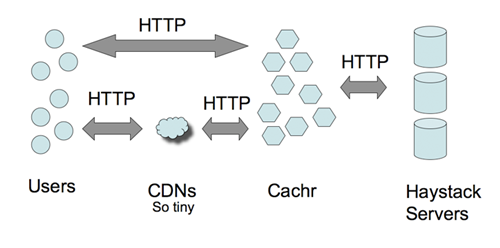
总体来看,Facebook 的图片处理还是采用成本偏高的方法来做的。技术含量貌似并不大。不清楚是否对图片作 Tweak,比如不影响图片质量的情况下减小图片尺寸。





相关推荐
Hive存储海量数据在Hadoop系统中,提供了一套类数据库的数据存储和处理机制。它采用类SQL语言对数据进行自动化管理和处理,经过语句解析和转换,最终生成基于Hadoop的MapReduce任务,通过执行这些任务完成数据处理。...
大数据处理平台 汇报人: 刘宏志 liuhz@pku.edu.cn 北京大学 软件与微电子学院 提纲 动机:为什么需要大数据处理平台 大数据处理平台的特点 大数据处理平台的架构 三种不同大数据的处理 传统计算:单机计算 特点: ...
Spark:尽管MapReduce和Hive能完成海量数据的⼤多数批处理⼯作,并且在打数据时代称为企业⼤数据处理的⾸选技术,但是其 数据查询的延迟⼀直被诟病,⽽且也⾮常不适合迭代计算和DAG(有限⽆环图)计算。由于Spark具有...
存储海量的数据并对其进行处理,而这正是Hadoop 的强项。如Facebook 使用Hadoop 存储 内部的日志拷贝,以及数据挖掘和日志统计;Yahoo !利用Hadoop 支持广告系统并处理网页 搜索;Twitter 则使用Hadoop 存储微博...
数据存储技术 数据采集与存储技术研究现状 传统关系数据库 应用场景局限 – 面向结构化数据,致力于数据处理,保证严格 一致性 缺乏对海量数据的快速访问能力 – 根据列值来定位行,输入输出耗时 – 范式设计与web...
近段时间以来,通过接触有关海量数据处理和搜索引擎的诸多技术,常常见识到不少精妙绝伦的架构图。除了每每感叹于每幅图表面上的绘制的精细之外,更为架构图背后所隐藏的设计思想所叹服。个人这两天一直在搜集各大型...
导读:毫无疑问,作为全球最领先的社交网络,Facebook的高性能集群系统承担了海量数据的处理,它的服务器架构一直为业界众人所关注。Facebook的架构可以从不同角度来换分层次。一种是:一边是PHP整的经典的LAMPstack...
通过使用分布式查询,可以快速高效的完成海量数据的查询。 Presto不仅可以访问HDFS,也可以操作不同的数据源,包括:RDBMS和其他的数据源(例如:Cassandra)。 Presto还支持数据联邦,可以在不同的数据源之间进行...
互联⽹企业的海量数据采集⼯具,有Facebook开源的Scribe、LinkedIn开源的 Kafka、淘宝开源的Timetunnel、Hadoop的Chukwa等,均可以满⾜每秒数百MB的⽇志数据采集和传输需求,并将这些数据上载到Hadoop 中央系统上。...
近段时间以来,通过接触有关海量数据处理和搜索引擎的诸多技术,常常见识到不少精妙绝伦的架构图。除了每每感叹于每幅图表面上的绘制的精细之外,更为架构图背后所隐藏的设计思想所叹服。个人这两天一直在搜集各大型...
Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。 Hadoop 采用 MapReduce 分布式计算框架,根据 GFS 原理开发...
(1)Hadoop Hadoop是效仿谷歌FileSystem和谷歌MapReduce而实现的一套海量数据分布式处理的开源软件框架,被广泛部署运用于雅虎、Facebook等互联网企业。目前,运行于雅虎的Hadoop集群被广泛用于雅虎广告、财经数据...
大数据是什么 大数据(big data,mega data),或称巨量资料,指的是需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。 大数据与云计算的关系就像一枚硬币的正反面一样...
近年来随着云计算、大数据处理、数据挖掘等概念和应用越来越火,Hadoop更是名声大噪,各大企业对熟悉Hadoop体系架构和性能优化的人才需求也相当旺盛,人才缺口也相对加大。 R语言可能对大多数人来说比较陌生,但是做...
而多格式数据、读写速度(读写速度是指数据从端点移动到处理器和存储的速度)以及海量数据是企业面临大数据处理急需解决的技术挑战。众所周知随着大容量数据(TB级、PB级甚至EB级)的出现,业务数据对IT系统带来了...
Value 价值 挖掘大数据的价值类似沙里淘金,从海量数据中挖掘稀疏但珍贵的信息. 价值密度低,是大数据的一个典型特征. 2010年海地地震,海地人散落在全国各地,援助人员为弄 清该去哪里援助手忙脚乱。传统上,他们...
Web请求异步处理和海量数据即时分析在淘宝开放平台的实践 岑文初 pdf 把大象放进冰箱 技术型复杂项目的特性裂解 pdf 阿里巴巴 B2B 的服务框架探索 钱霄 pdf 阿里巴巴中文站架构设计实践 何崚 pdf">云计算系统...
在过去二十年中,计算能力的稳步增强催生了铺天盖地的数据量,这反过来引起计算架构和大型数据处理机制的范式转换。例如,天文学中的强大望远镜、物理学中的粒子加速器、生物学中的基因组测序系统都将海量数据交到了...