ињСжЬЯй°єзЫЃйЬАи¶БпЉМеБЪдЇЖдЄАжЃµжЧґйЧізЪДSQL ServerжАІиГљдЉШеМЦпЉМйБЗеИ∞дЇЖдЄАдЇЫйЧЃйҐШпЉМдєЯзІѓзіѓдЇЖдЄАдЇЫзїПй™МпЉМзО∞жАїзїУдЄАдЄЛпЉМдЄОеРЫеЕ±дЇЂгАВSQL ServerжАІиГљдЉШеМЦжґЙеПКеИ∞иЃЄе§ЪжЦєйЭҐпЉМе¶ВиЙѓе•љзЪДз≥їзїЯеТМжХ∞жНЃеЇУиЃЊиЃ°пЉМдЉШиі®зЪДSQLзЉЦеЖЩпЉМеРИйАВзЪДжХ∞ж́谮糥еЉХиЃЊиЃ°пЉМзФЪиЗ≥еРДзІНз°ђдїґеЫ†зі†пЉЪзљСзїЬжАІиГљгАБжЬНеК°еЩ®зЪДжАІиГљгАБжУНдљЬз≥їзїЯзЪДжАІиГљпЉМзФЪиЗ≥зљСеН°гАБдЇ§жНҐжЬЇз≠ЙгАВињЩзѓЗжЦЗзЂ†дЄїи¶БиЃ≤еИ∞е¶ВдљХжФєеЦД糥еЉХпЉМињШе∞ЖжЬЙеП¶дЄАзѓЗиЃ®иЃЇе¶ВдљХжФєеЦДSQLиѓ≠еП•гАВ
й¶ЦеЕИйЬАи¶БеЉЇи∞ГдЄАдЄЛпЉМж∞іиГљиљљиИЯпЉМдЇ¶иГљи¶ЖиИЯгАВеїЇзЂЛвАЬйАВељУвАЭзЪД糥еЉХжШѓеЃЮзО∞жߕ胥дЉШеМЦзЪДй¶Ци¶БеЙНжПРгАВ
ељУж†єж́糥еЉХз†БзЪДеАЉжРЬ糥жХ∞жНЃжЧґпЉМ糥еЉХжПРдЊЫдЇЖеѓєжХ∞жНЃзЪДењЂйАЯиЃњйЧЃгАВдЇЛеЃЮдЄКпЉМж≤°жЬЙ糥еЉХ,жХ∞жНЃеЇУдєЯиГљж†єжНЃSELECTиѓ≠еП•жИРеКЯеЬ∞ж£А糥еИ∞зїУжЮЬпЉМдљЖйЪПзЭАи°®еПШеЊЧиґКжЭ•иґКе§ІпЉМдљњзФ®вАЬйАВељУвАЭзЪД糥еЉХзЪДжХИжЮЬе∞±иґКжЭ•иґКжШОжШЊгАВ糥еЉХжЬЙеК©дЇОжПРйЂШж£А糥жАІиГљпЉМдљЖињЗе§ЪжИЦдЄНељУзЪД糥еЉХдєЯдЉЪеѓЉиЗіз≥їзїЯдљОжХИгАВеЫ†дЄЇзФ®жИЈеЬ®и°®дЄ≠жѓПеК†ињЫдЄА䪙糥еЉХпЉМжХ∞жНЃеЇУе∞±и¶БеБЪжЫіе§ЪзЪДеЈ•дљЬгАВињЗе§ЪзЪД糥еЉХзФЪиЗ≥дЉЪеѓЉиdz糥еЉХзҐОзЙЗгАВжЙАдї•пЉМи¶БеїЇзЂЛдЄАдЄ™вАЬйАВељУвАЭзЪД糥еЉХдљУз≥їпЉМзЙєеИЂжШѓеѓєиБЪеРИ糥еЉХзЪДеИЫеїЇпЉМжЫіеЇФз≤ЊзЫКж±Вз≤ЊпЉМдї•дљњжХ∞жНЃеЇУиГљеЊЧеИ∞йЂШжАІиГљзЪДеПСжМ•гАВ
зЃАињ∞SQL ServerзЪД糥еЉХ
SQL ServerжПРдЊЫдЇЖдЄ§зІН糥еЉХпЉЪиБЪйЫЖ糥еЉХпЉИclustered indexпЉМдєЯзІ∞иБЪ籿糥еЉХгАБз∞ЗйЫЖ糥еЉХпЉЙеТМйЭЮиБЪйЫЖ糥еЉХпЉИnonclustered indexпЉМдєЯзІ∞йЭЮиБЪ籿糥еЉХгАБйЭЮз∞ЗйЫЖ糥еЉХпЉЙгАВ
иБЪйЫЖ糥еЉХз°ЃеЃЪи°®дЄ≠жХ∞жНЃзЪДзЙ©зРЖй°ЇеЇПгАВиБЪйЫЖ糥еЉХз±їдЉЉдЇОзФµиѓЭз∞њпЉМеРОиАЕжМЙеІУж∞ПжОТеИЧжХ∞жНЃгАВзФ±дЇОиБЪйЫЖ糥еЉХиІДеЃЪжХ∞жНЃеЬ®и°®дЄ≠зЪДзЙ©зРЖе≠ШеВ®й°ЇеЇПпЉМеЫ†ж≠§дЄАдЄ™и°®еП™иГљеМЕеРЂдЄАдЄ™иБЪйЫЖ糥еЉХгАВдљЖ胕糥еЉХеПѓдї•еМЕеРЂе§ЪдЄ™еИЧпЉИзїДеРИ糥еЉХпЉЙпЉМе∞±еГПзФµиѓЭз∞њжМЙеІУж∞ПеТМеРНе≠ЧињЫи°МзїДзїЗдЄАж†ЈгАВ
иБЪйЫЖ糥еЉХеѓєдЇОйВ£дЇЫзїПеЄЄи¶БжРЬ糥иМГеЫіеАЉзЪДеИЧзЙєеИЂжЬЙжХИгАВдљњзФ®иБЪйЫЖ糥еЉХжЙЊеИ∞еМЕеРЂзђђдЄАдЄ™еАЉзЪДи°МеРОпЉМдЊњеПѓдї•з°ЃдњЭеМЕеРЂеРОзї≠糥еЉХеАЉзЪДи°МеЬ®зЙ©зРЖзЫЄйВїгАВдЊЛе¶ВпЉМе¶ВжЮЬеЇФзФ®з®ЛеЇПжЙІи°МзЪДдЄАдЄ™жߕ胥зїПеЄЄж£А糥жЯРдЄАжЧ•жЬЯиМГеЫіеЖЕзЪДиЃ∞ељХпЉМеИЩдљњзФ®иБЪйЫЖ糥еЉХеПѓдї•ињЕйАЯжЙЊеИ∞еМЕеРЂеЉАеІЛжЧ•жЬЯзЪДи°МпЉМзДґеРОж£А糥谮дЄ≠жЙАжЬЙзЫЄйВїзЪДи°МпЉМзЫіеИ∞еИ∞иЊЊзїУжЭЯжЧ•жЬЯгАВињЩж†ЈжЬЙеК©дЇОжПРйЂШж≠§з±їжߕ胥зЪДжАІиГљгАВеРМж†ЈпЉМе¶ВжЮЬеѓєдїОи°®дЄ≠ж£А糥зЪДжХ∞жНЃињЫи°МжОТеЇПжЧґзїПеЄЄи¶БзФ®еИ∞жЯРдЄАеИЧпЉМеИЩеПѓдї•е∞Жиѓ•и°®еЬ®иѓ•еИЧдЄКиБЪйЫЖпЉИзЙ©зРЖжОТеЇПпЉЙпЉМйБњеЕНжѓПжђ°жߕ胥胕еИЧжЧґйГљињЫи°МжОТеЇПпЉМдїОиАМиКВзЬБжИРжЬђгАВ
йЭЮиБЪйЫЖ糥еЉХдЄОиѓЊжЬђдЄ≠зЪД糥еЉХз±їдЉЉгАВжХ∞жНЃе≠ШеВ®еЬ®дЄАдЄ™еЬ∞жЦєпЉМ糥еЉХе≠ШеВ®еЬ®еП¶дЄАдЄ™еЬ∞жЦєпЉМ糥еЉХеЄ¶жЬЙжМЗйТИжМЗеРСжХ∞жНЃзЪДе≠ШеВ®дљНзљЃгАВ糥еЉХдЄ≠зЪДй°єзЫЃжМЙ糥еЉХйФЃеАЉзЪДй°ЇеЇПе≠ШеВ®пЉМиАМи°®дЄ≠зЪДдњ°жБѓжМЙеП¶дЄАзІНй°ЇеЇПе≠ШеВ®пЉИињЩеПѓдї•зФ±иБЪйЫЖ糥еЉХиІДеЃЪпЉЙгАВе¶ВжЮЬеЬ®и°®дЄ≠жЬ™еИЫеїЇиБЪйЫЖ糥еЉХпЉМеИЩжЧ†ж≥ХдњЭиѓБињЩдЇЫи°МеЕЈжЬЙдїїдљХзЙєеЃЪзЪДй°ЇеЇПгАВ
жЫіиѓ¶зїЖзЪДдїЛзїНиѓЈеПВиАГMSDNдЄКеЕ≥дЇО糥еЉХзЪДдїЛзїНгАВhttp://msdn.microsoft.com/zh-cn/library/ms189271.aspx
дљњзФ®SQL ServerзЪД糥еЉХ
йЧЃйҐШеПИжЭ•дЇЖпЉМжЧҐзДґеИЖдЇЖдЄ§зІН糥еЉХпЉМдљХжЧґдљХзІНжГЕеЖµзФ®дљХзІН糥еЉХпЉЯйВ£е∞±зЬЛзЬЛдЄЛи°®еРІгАВзЃАеНХзЪДиѓіе∞±жШѓпЉЪеѓєдЇОе∞ПжХ∞зЫЃзЪДдЄНеРМеАЉпЉМжИЦеИЧзїП媪襀еИЖзїДжОТеЇПпЉМжИЦйЬАи¶БињФеЫЮжЯРиМГеЫіеЖЕзЪДжХ∞жНЃжЧґдљњзФ®иБЪйЫЖ糥еЉХпЉЫеѓєдЇОе§ІжХ∞зЫЃзЪДдЄНеРМеАЉпЉМжИЦеИЧзїП媪襀еИЖзїДжОТеЇПпЉМжИЦеИЧ襀йҐСзєБжЫіжЦ∞жЧґдљњзФ®йЭЮиБЪйЫЖ糥еЉХгАВ
|
|
дљњзФ®иБЪйЫЖ糥еЉХ
|
дљњзФ®йЭЮиБЪйЫЖ糥еЉХ
|
|
еИЧзїП媪襀еИЖзїДжОТеЇП
|
еЇФ
|
еЇФ
|
|
ињФеЫЮжЯРиМГеЫіеЖЕзЪДжХ∞жНЃ
|
еЇФ
|
дЄНеЇФ
|
|
дЄАдЄ™жИЦжЮБе∞СдЄНеРМеАЉ
|
дЄНеЇФ
|
дЄНеЇФ
|
|
е∞ПжХ∞зЫЃзЪДдЄНеРМеАЉ
|
еЇФ
|
дЄНеЇФ
|
|
е§ІжХ∞зЫЃзЪДдЄНеРМеАЉ
|
дЄНеЇФ
|
еЇФ
|
|
йҐСзєБжЫіжЦ∞зЪДеИЧ
|
дЄНеЇФ
|
еЇФ
|
|
е§ЦйФЃеИЧ
|
еЇФ
|
еЇФ
|
|
дЄїйФЃеИЧ
|
еЇФ
|
еЇФ
|
|
йҐСзєБдњЃжԺ糥еЉХеИЧ
|
дЄНеЇФ
|
еЇФ
|
е¶ВдљХжФєеЦД糥еЉХзЪДдЄАдЇЫзїПй™МпЉЪ
1.糥еЉХй¶ЦеЕИи¶Бжї°иґ≥дљ†зЪДеЇФзФ®дЄ≠жЬАеЕ≥йФЃжИЦиАЕж؃襀еЊИе§ЪзФ®жИЈйҐСзєБжЙІи°МзЪДжߕ胥гАВ
иЛ•жЯРдЄ™жߕ胥жѓПжЬИдїЕжЙІи°МдЄАжђ°пЉМи¶БиАГиЩСжШѓеР¶еАЉеЊЧдЄЇеЕґжґЙеПКи°®еИЫеїЇдЇЖ糥еЉХгАВи¶БзЯ•йБУеЬ®ељУжЬИзЪДеЕґеЃГжЧґйЧіжХ∞жНЃеЇУз≥їзїЯ僺胕糥еЉХзЪДзїіжК§еЉАйФАжШѓи¶БиґЕињЗжї°иґ≥иѓ•жߕ胥зЪДи°®жЙЂжППзЪДеЉАйФАзЪДгАВжЙАдї•пЉМе•љйТҐзФ®еЬ®еИАеИГдЄКпЉМ啚糥еЉХзФ®еЬ®еЕ≥йФЃйҐСзєБзЪДжߕ胥дЄКгАВ
2.еЬ®зїПеЄЄињЫи°МињЮжО•пЉМдљЖжШѓж≤°жЬЙжМЗеЃЪдЄЇе§ЦйФЃзЪДеИЧдЄКеїЇзЂЛ糥еЉХгАВ
еЬ®еµМе•Чжߕ胥дЄ≠пЉМеѓєи°®зЪДй°ЇеЇПе≠ШеПЦеѓєжߕ胥жХИзОЗеПѓиГљдЇІзФЯиЗіеСљзЪДељ±еУНгАВжѓФе¶ВйЗЗзФ®й°ЇеЇПе≠ШеПЦз≠ЦзХ•пЉМдЄАдЄ™еµМе•Ч3е±ВзЪДжߕ胥пЉМе¶ВжЮЬжѓПе±ВйГљжߕ胥1000и°МпЉМйВ£дєИињЩдЄ™жߕ胥е∞±и¶Бжߕ胥10дЇњи°МжХ∞жНЃгАВйБњеЕНињЩзІНжГЕеЖµзЪДдЄїи¶БжЦєж≥Хе∞±жШѓеѓєињЮжО•зЪДеИЧињЫи°М糥еЉХгАВдЊЛе¶ВдЄЛйЭҐзЪДдЄАжЭ°SQLпЉМињЮжО•ињЩдЄ§дЄ™и°®пЉЪtblAпЉИid, c1, c2, вА¶пЉЙеТМtblBпЉИid, вА¶пЉЙпЉМе∞±йЬАи¶БеИЖеИЂеЬ®дЄ§дЄ™и°®зЪДidе≠ЧжЃµдЄКеїЇзЂЛ糥еЉХгАВ
 selecta.id,a.c1,a.c2,вА¶fromtblAawhereexists(select1fromtblBbwhereb.id=a.id)
selecta.id,a.c1,a.c2,вА¶fromtblAawhereexists(select1fromtblBbwhereb.id=a.id)
3.жОТеЇПжИЦеИЖзїД僺糥еЉХзЪДељ±еУН
¬Ј еЬ®йҐСзєБињЫи°МжОТеЇПжИЦеИЖзїДпЉИеН≥ињЫи°Мgroup byжИЦorder byжУНдљЬпЉЙзЪДеИЧдЄКеїЇзЂЛ糥еЉХгАВе¶ВжЮЬеЊЕжОТеЇПзЪДеИЧжЬЙе§ЪдЄ™пЉМеПѓдї•еЬ®ињЩдЇЫеИЧдЄКеїЇзЂЛе§НеРИ糥еЉХгАВ
¬Ј 糥еЉХдЄ≠дЄАеЃЪи¶БеМЕеРЂжЙАжЬЙзЪДgroup byжИЦorder byжУНдљЬеИЧпЉМдЄФgroup byжИЦorder byжУНдљЬеИЧдЄ≠еИЧзЪДжђ°еЇПдЄАеЃЪи¶БдЄО糥еЉХдЄ≠зЪДжђ°еЇПзЫЄеРМгАВ
¬Ј зЃАеМЦжИЦйБњеЕНеѓєе§ІжХ∞жНЃйЗПи°®зЪДжОТеЇПгАВељУиГље§ЯеИ©зԮ糥еЉХиЗ™еК®дї•йАВељУзЪДжђ°еЇПдЇІзФЯиЊУеЗЇжЧґпЉМдЉШеМЦеЩ®е∞±йБњеЕНдЇЖжОТеЇПзЪДж≠•й™§гАВ
¬Ј жОТеЇПзЪДеИЧиЛ•жЭ•иЗ™дЄНеРМзЪДи°®пЉМеРМж†ЈдЉЪеЬ®жЙІи°МиЃ°еИТдЄ≠еЉХиµЈдЄАдЄ™жОТеЇПзЪДеЉАйФАгАВдЄЇдЇЖйБњеЕНдЄНењЕи¶БзЪДжОТеЇПпЉМе∞±и¶Бж≠£з°ЃеЬ∞еҐЮ忯糥еЉХпЉМеРИзРЖеЬ∞еРИеєґжХ∞жНЃеЇУи°®пЉИе∞љзЃ°жЬЙжЧґеПѓиГљељ±еУНи°®зЪДиІДиМГеМЦпЉМдљЖзЫЄеѓєдЇОжХИзОЗзЪДжПРйЂШжШѓеАЉеЊЧзЪДпЉЙгАВе¶ВжЮЬжОТеЇПдЄНеПѓйБњеЕНпЉМйВ£дєИеЇФељУиѓХеЫЊзЃАеМЦеЃГпЉМе¶ВзЉ©е∞ПжОТеЇПзЪДеИЧзЪДиМГеЫіз≠ЙгАВ
4.йЭЮйїСеН≥зЩље∞±еȀ糥еЉХдЇЖ
еЬ®жЭ°дїґи°®иЊЊеЉПдЄ≠зїПеЄЄзФ®еИ∞зЪДдЄНеРМеАЉиЊГе§ЪзЪДеИЧдЄКеїЇзЂЛйЭЮиБЪйЫЖ糥еЉХпЉМеЬ®дЄНеРМеАЉеЊИе∞СзЪДеИЧдЄКе∞±дЄНи¶БеїЇзЂЛ糥еЉХдЇЖгАВжѓФе¶ВеЬ®жЯРи°®зЪДвАЬзКґжАБвАЭеИЧдЄКеП™жЬЙвАЬжШѓвАЭдЄОвАЬеР¶вАЭдЄ§дЄ™дЄНеРМеАЉпЉМе∞±ж≤°ењЕи¶БеїЇдЇЖпЉМеЫ†дЄЇж≠§жЧґи°®жЙЂжППжЭ•еЊЧжЫіжЬЙжХИгАВиЛ•еїЇдЇЖ糥еЉХпЉМдЄНдљЖжߕ胥жХИзОЗж≤°жПРйЂШпЉМеПНиАМдЄ•йЗНйЩНдљОдЇЖжЫіжЦ∞йАЯеЇ¶гАВ
5.вАЬ糥еЉХи¶ЖзЫЦвАЭжШѓжАОж†ЈзВЉжИРзЪД
еѓєжЯРдЄ™и°®tblAеїЇдЇЖдЄ™иБЪйЫЖ糥еЉХtblA_idx(c1, c2, c3)гАВињЩж†ЈеЃЮйЩЕдЄКжШѓеїЇзЂЛдЇЖдЄЙ䪙糥еЉХпЉЪ(c1), (c1, c2), (c1, c2, c3)гАВ
selectmin(c1)fromtblAwherec1>1--дЉЪиІ¶еПСClusteredIndexSeekгАВ
selectmin(c1)fromtblAwherec1>1andc2=2--дЉЪиІ¶еПСClusteredIndexSeekгАВ
selectmin(c1)fromtblAwherec1>1andc3<3--дЉЪиІ¶еПСClusteredIndexScanгАВ
selectmin(c1)fromtblAwherec2=2andc3<3--дЉЪиІ¶еПСClusteredIndexScanгАВ
selectmin(c1)fromtblAwherec1>1andc2=2andc3<3--дЉЪиІ¶еПСClusteredIndexSeekпЉМдЄФ嚥жИРдЇЖ糥еЉХи¶ЖзЫЦгАВ
еЕґдЄ≠Clustered Index ScanзЪДжЙІи°МиЃ°еИТ

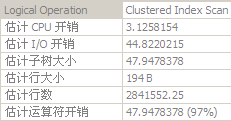
еЕґдЄ≠Clustered Index SeekзЪДжЙІи°МиЃ°еИТ


е¶Вж≠§еПѓиІБ嚥жИР糥еЉХи¶ЖзЫЦзЪДењЕи¶БжАІгАВ
6.йЭЮиБЪйЫЖ糥еЉХдЄОз≤Њз°ЃжЯ•жЙЊзЪДйїШе•С
еѓєдЇОжЯРдЄ™и°®дЄ≠зЪДжЯРдЄ™е≠ЧжЃµе≠ШеЬ®е§ІжХ∞зЫЃзЪДдЄНеРМеАЉжЧґпЉМдЄЇиѓ•е≠ЧжЃµеїЇдЄ™йЭЮиБЪйЫЖ糥еЉХдЉЪиЊЊеИ∞жДПжГ≥дЄНеИ∞зЪДжХИжЮЬгАВеЫ†дЄЇжХ∞жНЃеЇУз≥їзїЯеЬ®жРЬ糥жХ∞жНЃеАЉжЧґпЉМеЕИеѓєйЭЮиБЪйЫЖ糥еЉХињЫи°МжРЬ糥пЉМжЙЊеИ∞жХ∞жНЃеАЉеЬ®и°®дЄ≠зЪДдљНзљЃпЉМзДґеРОдїОиѓ•дљНзљЃзЫіжО•ж£А糥жХ∞жНЃгАВеۆ䪯糥еЉХеМЕеРЂжППињ∞жߕ胥жЙАжРЬ糥зЪДжХ∞жНЃеАЉеЬ®и°®дЄ≠зЪДз≤Њз°ЃдљНзљЃзЪДжЭ°зЫЃпЉМињЩдєЯжШѓдЄЇдїАдєИйЭЮиБЪйЫЖ糥еЉХжШѓз≤Њз°ЃеМєйЕНжߕ胥зЪДжЬАдљ≥жЦєж≥ХгАВдЊЛе¶ВпЉМеЬ®employeeи°®дЄЇemp_idеИЧеїЇдЇЖйЭЮиБЪйЫЖ糥еЉХпЉМи¶БжРЬ糥еЕґйЫЗеСШID (emp_id) > 1000зЪДжЙАжЬЙдЇЇпЉМSQL ServerдЉЪеܮ糥еЉХдЄ≠зЫіжО•иЈ≥еИ∞emp_id = 1000ињЩж†ЈдЄАдЄ™жЭ°зЫЃдєЛеРОпЉМеИЧеЗЇеМєйЕНзЪДemp_idеИЧеЬ®и°®дЄ≠зЪДй°µеТМи°МпЉМзДґеРОзЫіжО•иљђеИ∞иѓ•й°µиѓ•и°МгАВ
7.е¶ВжЮЬдљ†жШѓзЪЃе∞ФжЦѓпЉМSQL Server зЪДжЙІи°МиЃ°еИТе∞±жШѓжЬЧе§Ъ
SQL Server 2005зЪДMicrosoft SQL Server Management StudioеТМDatabase Engine Tuning AdvisorпЉИDETAпЉЙжШѓйЭЮеЄЄе•љзЪДжАІиГљи∞ГиѓХеК©жЙЛпЉМеПѓдї•дљњзФ®еЃГдїђеѓєSQLиѓ≠еП•и∞ГдЉШпЉМжЯ•зЬЛдЉ∞иЃ°зЪДжЙІи°МиЃ°еИТеЉАйФАпЉМзФ®DETAзФЯжИРдЉШеМЦеїЇиЃЃпЉМйЗЗзЇ≥жИЦеПВиАГ糥еЉХдЉШеМЦйГ®еИЖгАВ
йЬАи¶Бж≥®жДПзЪДжШѓпЉМеѓєдЇОдЉ∞иЃ°зЪДжЙІи°МиЃ°еИТпЉМдЄНи¶БињЗдЇОеЕ≥ж≥®йЗМйЭҐжШЊз§ЇзЪДеЉАйФАжѓФдЊЛпЉМиАМеЃЮйЩЕдЄКињЩдЄ™жЬЙжЧґдЉЪиѓѓеѓЉгАВжИСеЬ®еЃЮйЩЕдЉШеМЦињЗз®ЛдЄ≠е∞±иҐЂеПСзО∞пЉМдЄАдЄ™index scanзЪДжЙІи°Мй°єеЉАйФАеП™еН†25%пЉМеП¶дЄАдЄ™йФЃжЯ•жЙЊзЪДеЉАйФАеН†50%пЉМиАМйФЃжЯ•жЙЊйГ®еИЖж†єжЬђж≤°жЬЙеПѓдЉШеМЦзЪДпЉМSEEKи∞УиѓНе∞±жШѓID=XXXињЩдЄ™еїЇзЂЛеЬ®дЄїйФЃдЄКзЪДжЯ•жЙЊгАВиАМдїФзїЖеИЖжЮРеПѓдї•зЬЛеИ∞пЉМеРОиАЕCPUеЉАйФА0.00015пЉМI/OеЉАйФА0.0013гАВиАМеЙНиАЕеСҐпЉМCPUеЉАйФА1.4xxxx,I/OеЉАйФАдєЯињЬе§ІдЇОеРОиАЕгАВеЫ†ж≠§пЉМдЉШеМЦйЗНзВєеЇФиѓ•жФЊеЬ®еЙНиАЕгАВ
зљСдЄКињЩз±їзЪДжЦЗзЂ†еЊИе§ЪпЉМињЩйЗМе∞±дЄНеБЪиµШињ∞дЇЖгАВеПѓдї•еПВиАГдЄАзѓЗиЊГжЧ©зЪДжЦЗзЂ†пЉЪSQL ServerжАІиГљи∞ГдЉШеЕ•йЧ®пЉИеЫЊжЦЗзЙИпЉЙ
еП¶е§ЦињШжЬЙдЄАзѓЗдЄНйФЩзЪДжЦЗзЂ†пЉМеЕ±дЇЂеЬ®ињЩйЗМпЉЪжОҐиЃ®е¶ВдљХеЬ®жЬЙзЭА1000дЄЗжЭ°жХ∞жНЃзЪДMS SQL SERVERжХ∞жНЃеЇУдЄ≠еЃЮзО∞ењЂйАЯзЪДжХ∞жНЃжПРеПЦеТМжХ∞жНЃеИЖй°µ
еНЪжЦЗжЭ•жЇРпЉЪhttp://www.blogjava.net/allen-zhe/archive/2010/07/23/326966.html
еИЖдЇЂеИ∞пЉЪ





зЫЄеЕ≥жО®иНР
иґЕзЇІеЕ®йЭҐзЪДSQLserver2008 жХ∞жНЃеЇУжАІиГљдЉШеМЦ жЦєж≥Х
SQL Server жХ∞жНЃеЇУжКАжЬѓ---еЯЇз°АзѓЗпЉИT-SQLеЯЇз°АгАБжХ∞жНЃеЇУеЗ†жЬђжУНдљЬгАБSQL Server 2008жЦ∞зЙєжАІпЉЙгАБжХ∞жНЃеЇУеЃЙеЕ®пЉИSQL Server 2008 еЃЙеЕ®жХ∞жНЃ...гАБжХ∞жНЃеЇУжАІиГљдЉШеМЦпЉИжХ∞жНЃеЇУе≠ШеВ®дЄО糥еЉХгАБжХ∞жНЃжߕ胥гАБдЇЛеК°е§ДзРЖгАБжХ∞жНЃеЇУз≥їзїЯи∞ГдЉШ еЈ•еЕЈпЉЙ
жЈ±еЕ•зРЖиІ£SqlServer糥еЉХжЬЇеИґеПКеРИзРЖдЉШеМЦжХ∞жНЃеЇУ
sql serverпЉМжХ∞жНЃеЇУпЉМиѓХеЫЊдЄО糥еЉХпЉМдїЛзїНжЦЗж°£ sql serverпЉМжХ∞жНЃеЇУпЉМиѓХеЫЊдЄО糥еЉХпЉМдїЛзїНжЦЗж°£ sql serverпЉМжХ∞жНЃеЇУпЉМиѓХеЫЊдЄО糥еЉХпЉМдїЛзїНжЦЗж°£ sql serverпЉМжХ∞жНЃеЇУпЉМиѓХеЫЊдЄО糥еЉХпЉМдїЛзїНжЦЗж°£ sql serverпЉМжХ∞жНЃеЇУпЉМиѓХеЫЊдЄО糥еЉХпЉМдїЛзїН...
иµДжЇРеРНзІ∞пЉЪSQLServerжАІиГљдЉШеМЦзѓЗеЖЕеЃєзЃАдїЛпЉЪ¬†жЬђжЦЗж°£дЄїи¶БиЃ≤ињ∞зЪДжШѓSQLServerжАІиГљдЉШеМЦ;еЬ®иЙѓе•љзЪДжХ∞жНЃеЇУиЃЊиЃ°еЯЇз°АдЄКпЉМиГљжЬЙжХИеЬ∞дљњзԮ糥еЉХжШѓSQL ServerеПЦеЊЧйЂШжАІиГљзЪДеЯЇз°АпЉМSQL ServerйЗЗзФ®еЯЇдЇОдї£дїЈзЪДдЉШеМЦж®°еЮЛпЉМеЃГеѓєжѓПдЄАдЄ™жПРдЇ§зЪД...
йАВзФ®дЇОSQL server 2008 R2зЙИжЬђеПКдї•дЄКпЉМйЗНеїЇеЕ®йî糥еЉХ
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
жАІиГљдЄНе§ЯпЉМ糥еЉХжЭ•еЗС жАІиГљдЄНе•љпЉМ忯䪙糥еЉХе∞±дЉЪе•љпЉЯ 糥еЉХдЄАеЃЪиГљжПРеНЗжАІиГљпЉЯ йЂШжХИ糥еЉХжМЗеНЧ жПРйЂШ糥еЉХзЪДе≠ШеВ®жХИзОЗ йАЙжЛ©еРИйАВзЪД糥еЉХ еЗПе∞СдЇМжђ°жЯ•жЙЊ ...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ6зЂ† 糥еЉХдЄОжХ∞жНЃеЃМжХіжАІ пЉИеЕ±47й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ7зЂ† е≠ШеВ®ињЗз®ЛеТМиІ¶еПСеЩ® пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ8зЂ† е§ЗдїљеТМжБҐе§Н пЉИеЕ±38й°µпЉЙ SQLServerжХ∞жНЃеЇУжХЩз®Л зђђ9зЂ† SQL Server 2008...
иµДжЇРеРНзІ∞пЉЪSQL Server 2008жߕ胥жАІиГљдЉШеМЦеЖЕеЃєзЃАдїЛпЉЪжЬђдє¶йАЪињЗе§ІйЗПеЃЮдЊЛпЉМиѓ¶зїЖдїЛзїНдЇЖSQL ServerжХ∞жНЃеЇУз≥їзїЯдЉШеМЦзЪДеРДзІНжЦєж≥ХеТМжКАеЈІгАВеЖЕеЃєжґµзЫЦдЇЖжХ∞жНЃеЇУеЇФзФ®з≥їзїЯдЄ≠еРДзІНжАІиГљзУґйҐИзЪДи°®зО∞嚥еЉПеПКеЕґеПСзФЯзЪДж†єжЇРеТМиІ£еЖ≥жЦєж≥ХпЉМдїОз°ђдїґ...
SQL2005жАІиГљдЉШеМЦе§ІеЕ®пЉМsqlserverжАІиГљдЉШеМЦ,еМЕжЛђпЉЪдїАдєИеПЂеБЪ糥еЉХгАБеИ©зԮ糥еЉХдЉШеМЦsqlserverжߕ胥гАБдљњзФ®жХ∞жНЃеЇУеИЖеМЇи°®жПРйЂШз®ЛеЇПж£А糥жХИзОЗгАБжПРйЂШжХ∞жНЃеЇУжߕ胥жХИзОЗзЪДеЃЮзФ®жЦєж≥ХгАБSQLжХ∞жНЃињЫи°МжОТеЇПгАБеИЖзїДгАБзїЯиЃ°жКАеЈІпЉЫSQL Serverжߕ胥...
еЬ®еЇФзФ®з≥їзїЯдЄ≠,е∞§еЕґеЬ®иБФжЬЇдЇЛеК°е§ДзРЖз≥їзїЯдЄ≠,еѓєжХ∞жНЃжߕ胥еПКе§ДзРЖйАЯеЇ¶еЈ≤жИРдЄЇи°°йЗПеЇФзФ®з≥їзїЯжИРиі•зЪДж†ЗеЗЖгАВиАМйЗЗзԮ糥еЉХжЭ•еК†ењЂжХ∞жНЃе§ДзРЖйАЯеЇ¶дєЯжИРдЄЇеєње§ІжХ∞жНЃеЇУзФ®жИЈжЙАжО•еПЧзЪД...жЬђжЦЗе∞± SQL Server糥еЉХзЪДжАІиГљйЧЃйҐШињЫи°МдЇЖдЄАдЇЫеИЖжЮРеТМеЃЮиЈµгАВ
luceneдЄОsqlserverжХ∞жНЃеЇУеЃЮзО∞糥еЉХзЪДзЃАеНХеЃЮдЊЛluceneдЄОsqlserverжХ∞жНЃеЇУеЃЮзО∞糥еЉХзЪДзЃАеНХеЃЮдЊЛ